Core Contribution
A single survey framework that links autonomy levels, workflow stages, scientific-quality evaluation, and domain-conditioned ceilings.
1Huazhong University of Science and Technology 2Lehigh University 3Tsinghua University 4Wuhan University 5Salesforce Research 6Squirrel AI Learning
7Northwestern University 8Independent 9Shanghai Jiao Tong University 10University of California San Diego 11Chinese University of Hong Kong
12University of Illinois Chicago 13Stanford University 14Google Cloud AI Research 15Recursive Superintelligence 16Microsoft Research
Scientific research is moving from isolated AI assistance toward integrated, longer-horizon workflow automation. AutoResearch captures this transition by treating scientific discovery as a coordinated process spanning literature grounding, planning, experimentation, validation, and reporting. Rather than framing the field through disconnected capabilities such as search, coding, or writing alone, the survey argues that scientific autonomy must be understood at the workflow level. What matters is not only whether an AI system can perform a subtask, but how control, execution, and validation are distributed across the entire research loop. To organize this landscape, the paper proposes a five-level autonomy spectrum from L0 (Human Only) to L4 (AI-Autonomous), identifies five recurring technical workflow stages, and shifts evaluation toward scientific quality dimensions including novelty, validity, impact, reliability, and provenance. It also emphasizes that autonomy ceilings are domain-conditioned, varying substantially across computational, empirical, clinical, and social sciences.
A single survey framework that links autonomy levels, workflow stages, scientific-quality evaluation, and domain-conditioned ceilings.
The paper studies AutoResearch as a workflow system, not as a loose collection of isolated AI capabilities.
Benchmark accuracy is insufficient; the survey centers novelty, validity, impact, reliability, and provenance.
Autonomy ceilings differ sharply across scientific fields because the structure of evidence and validation differs.
Because this is a survey, the homepage foregrounds the paper's framing logic before drilling into subcomponents. The survey framework first establishes the conceptual map, then unfolds into autonomy, technical foundations, evaluation, and domain constraints.
The five-level autonomy spectrum is the paper's backbone. It distinguishes not only who performs research tasks, but who retains control, who executes, and who ultimately validates scientific claims.
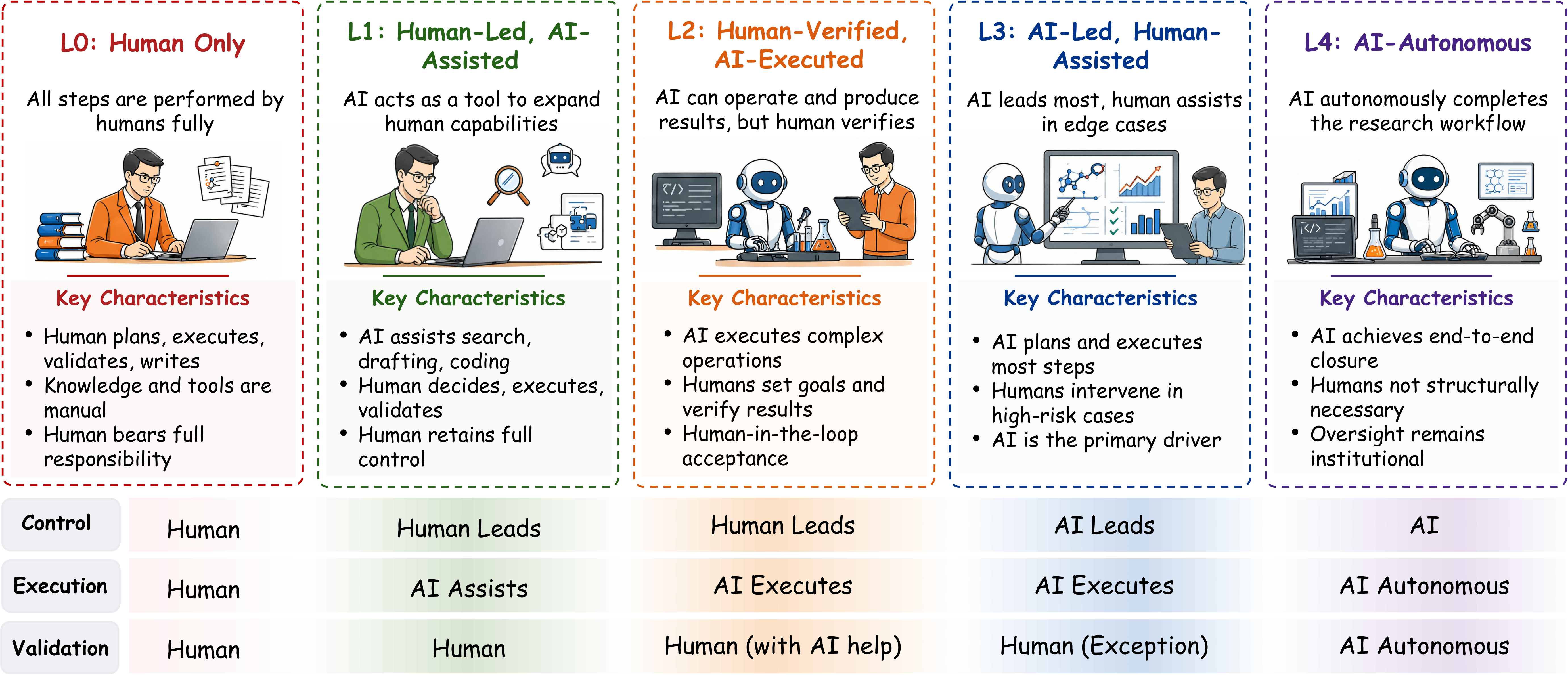
Humans plan, execute, and validate the full inquiry loop.
AI supports bounded cognitive work while humans retain end-to-end control.
AI executes substantial steps but humans still verify outputs and claims.
AI coordinates the workflow and humans mainly intervene for exceptional cases.
End-to-end scientific closure no longer structurally depends on human oversight.
The levels should not be read as a simple capability ladder. They encode changing distributions of scientific authority across control, execution, and validation, which is why the same system may appear strong in one stage but remain limited in full workflow autonomy.
The historical view situates representative systems on top of the autonomy spectrum. This makes the survey longitudinal: it does not just define levels, it also shows how research automation has evolved toward them over time.
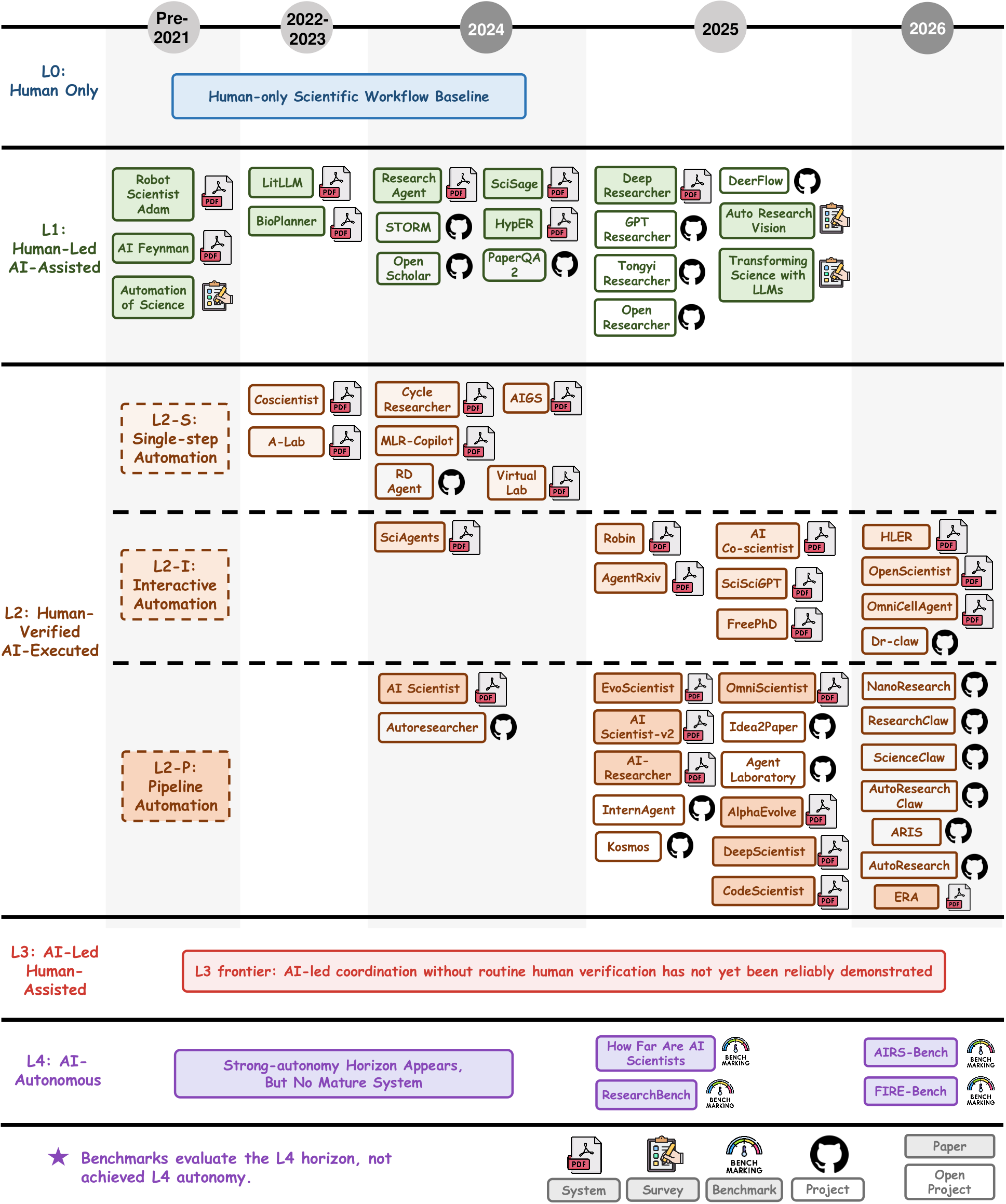
Instead of listing isolated methods, the survey decomposes AutoResearch into a recurring workflow. The five technical stages below are presented as a horizontal atlas so readers can scan the pipeline from grounding to reporting in one pass.
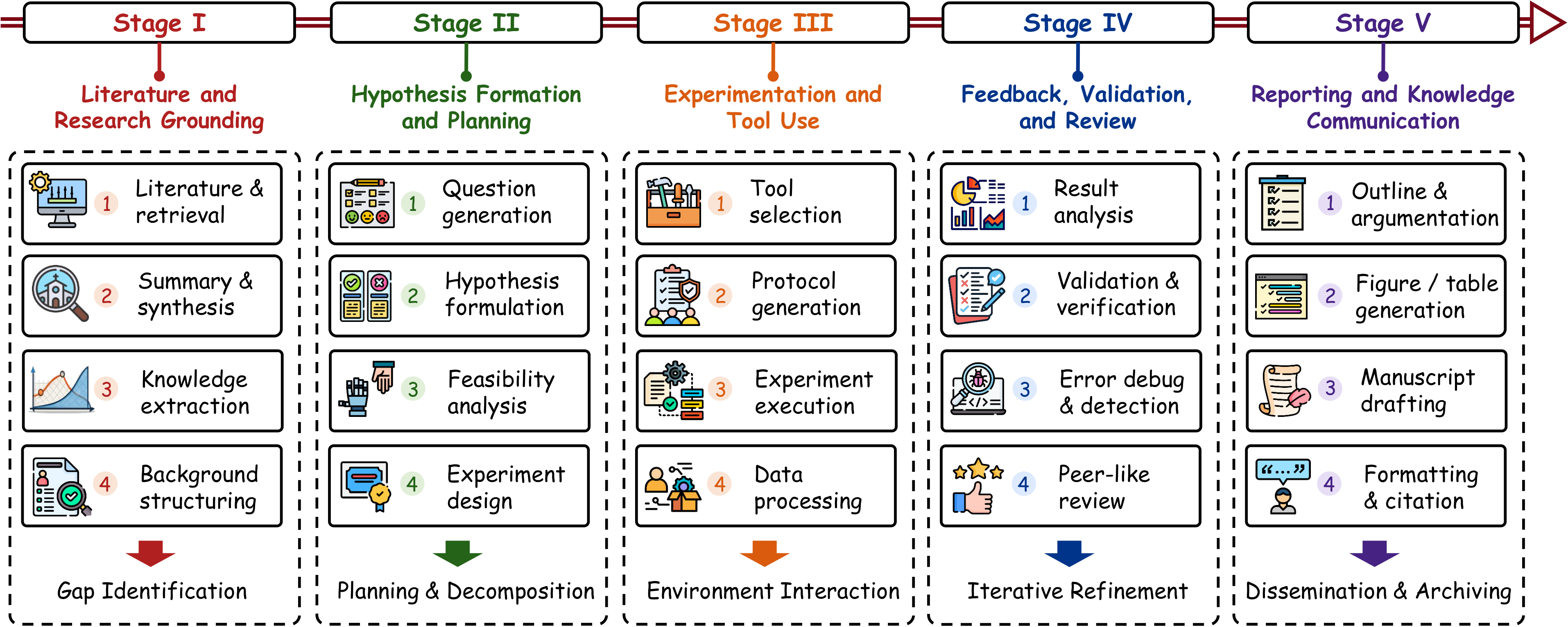
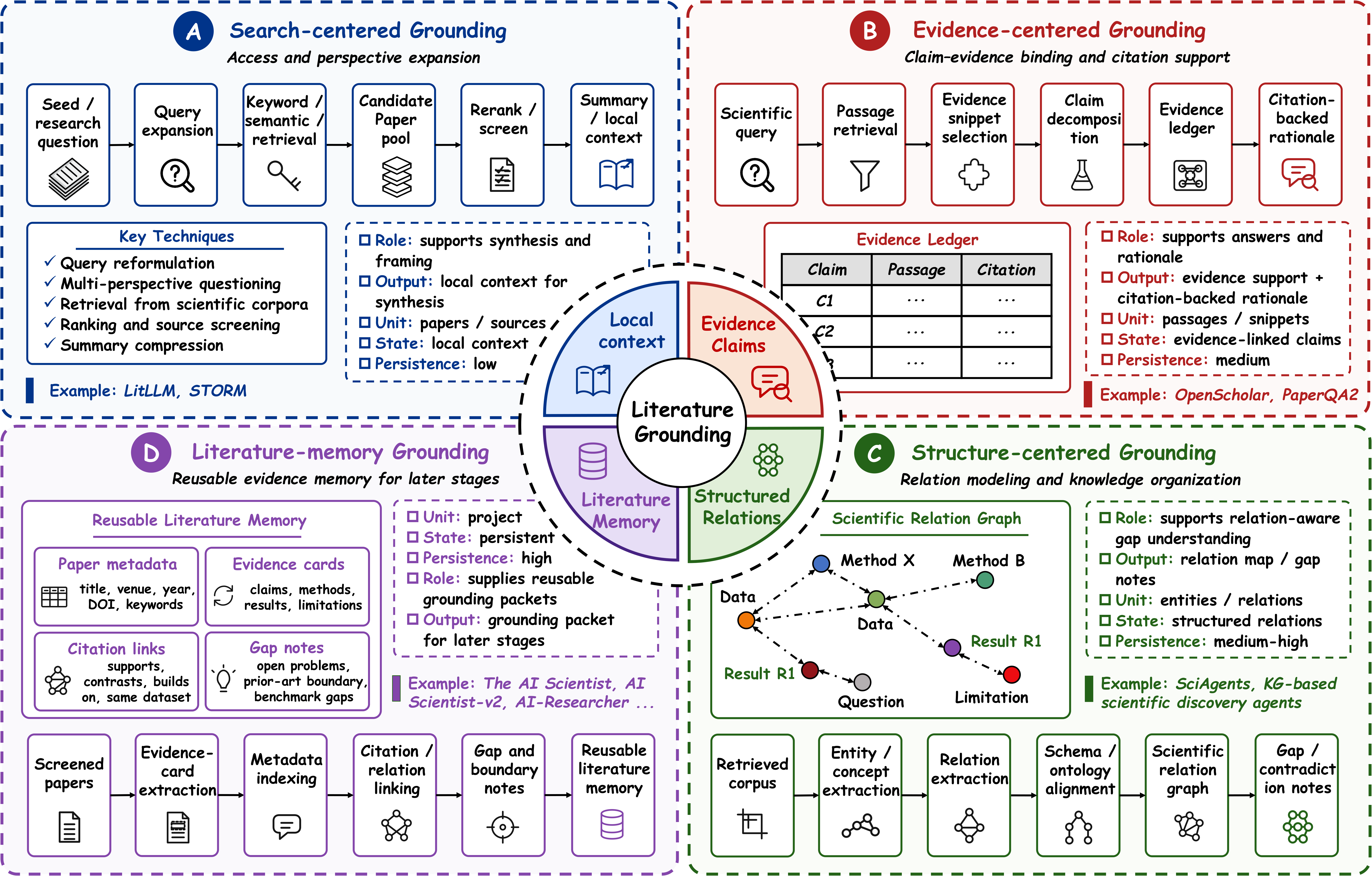
Anchors the workflow in search, evidence, and literature memory.
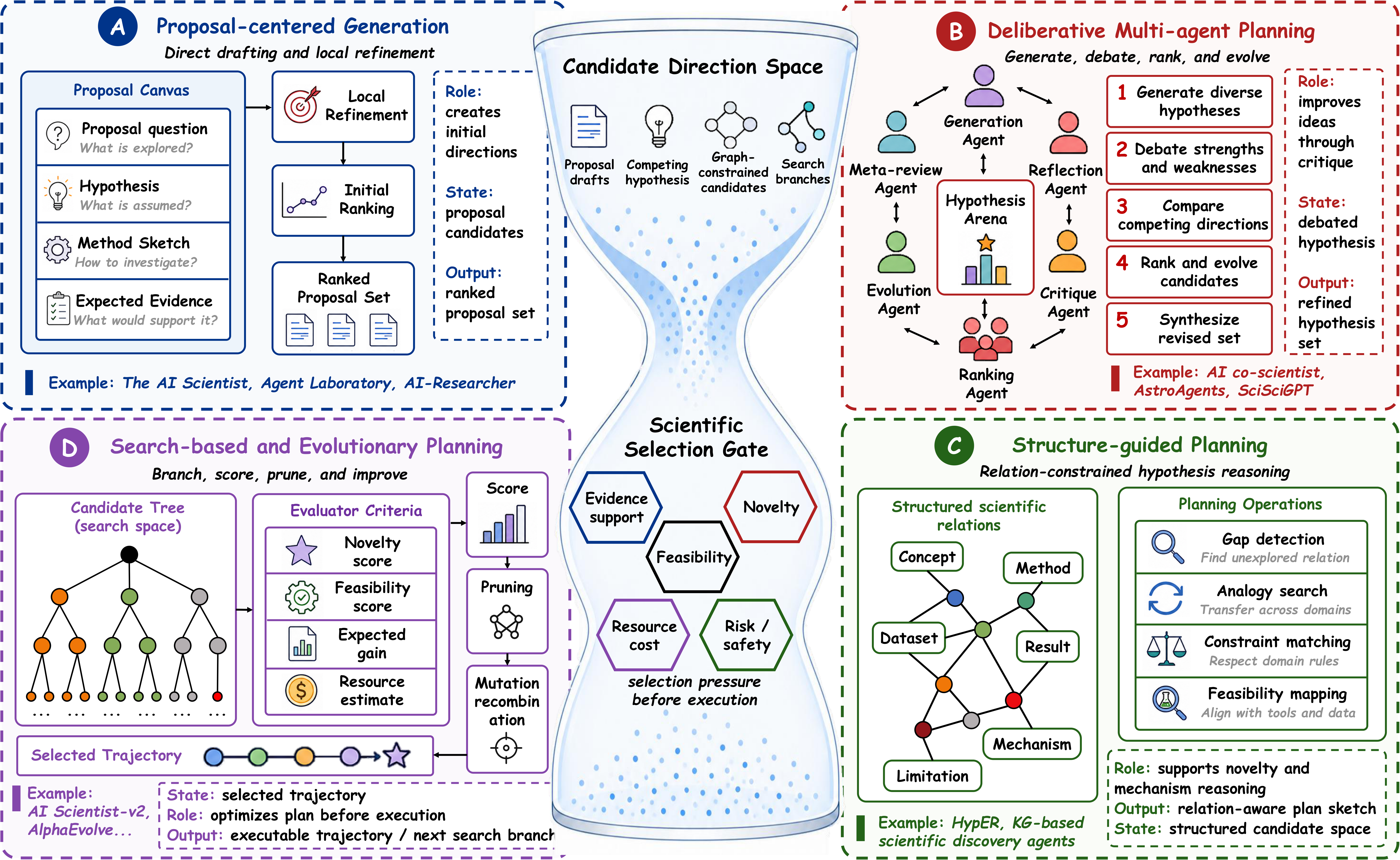
Transforms grounded context into operationalizable candidate directions.
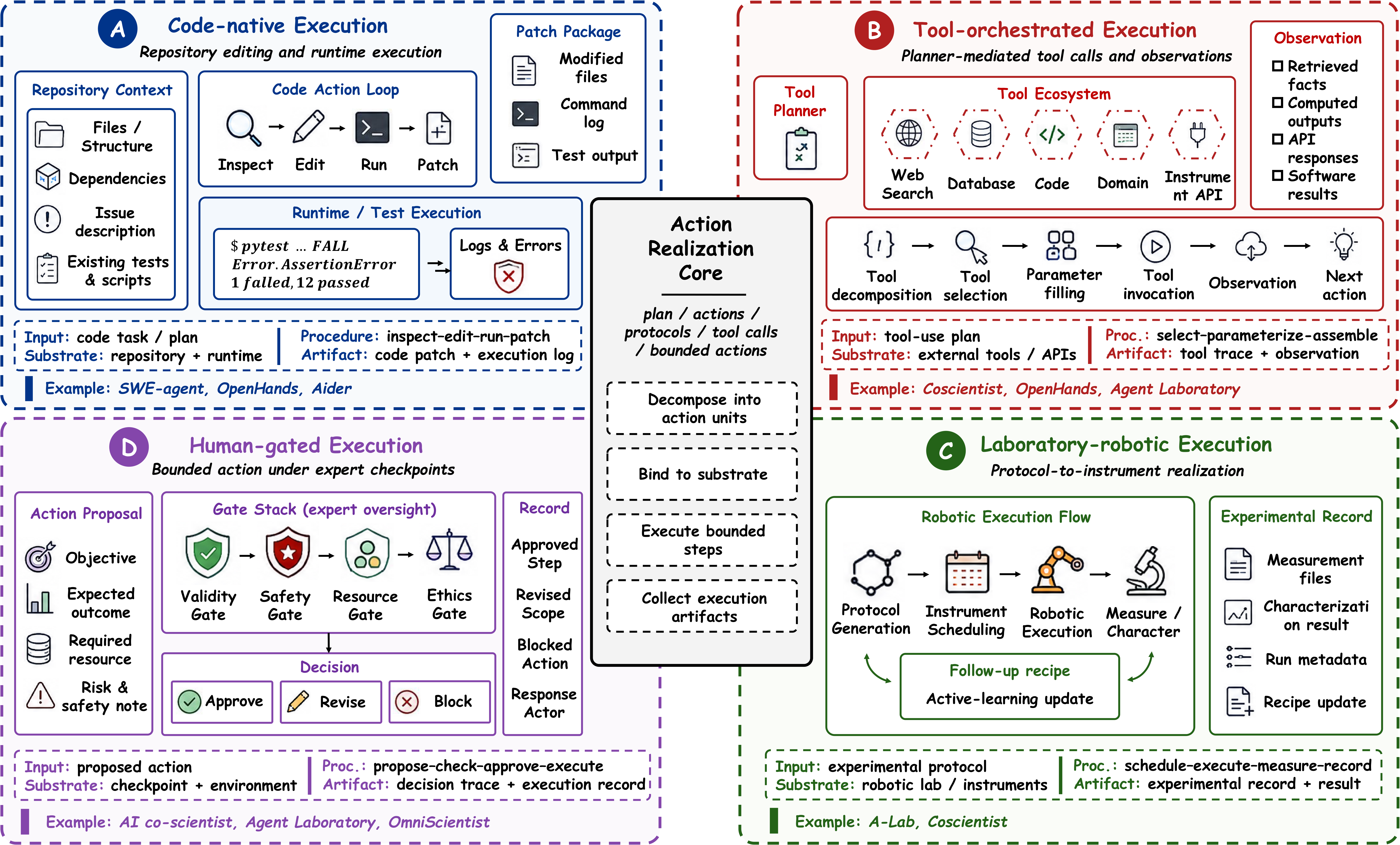
Binds plans to code, tools, simulators, and executable substrates.
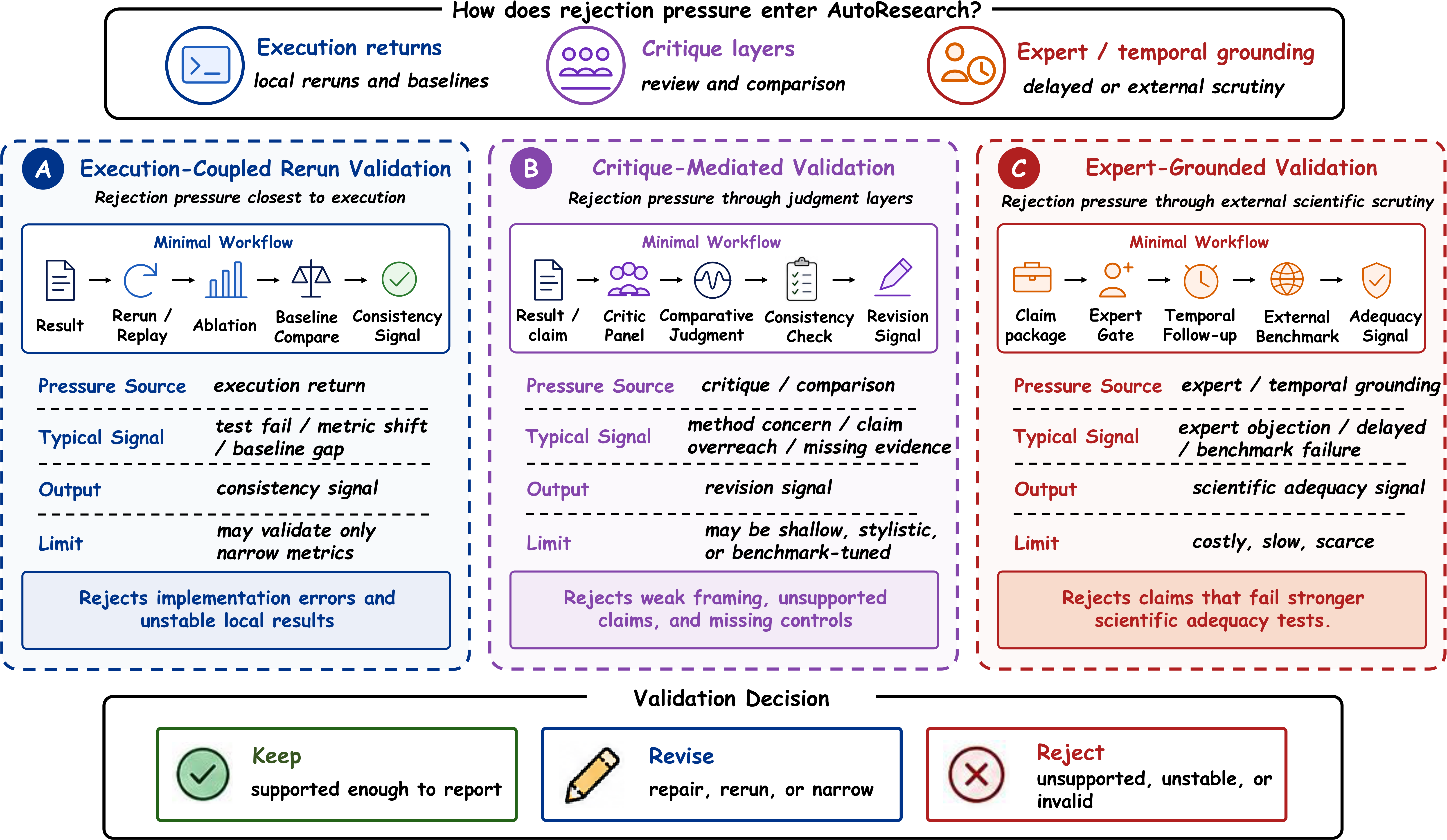
Introduces rejection pressure through reruns, critique, and review.
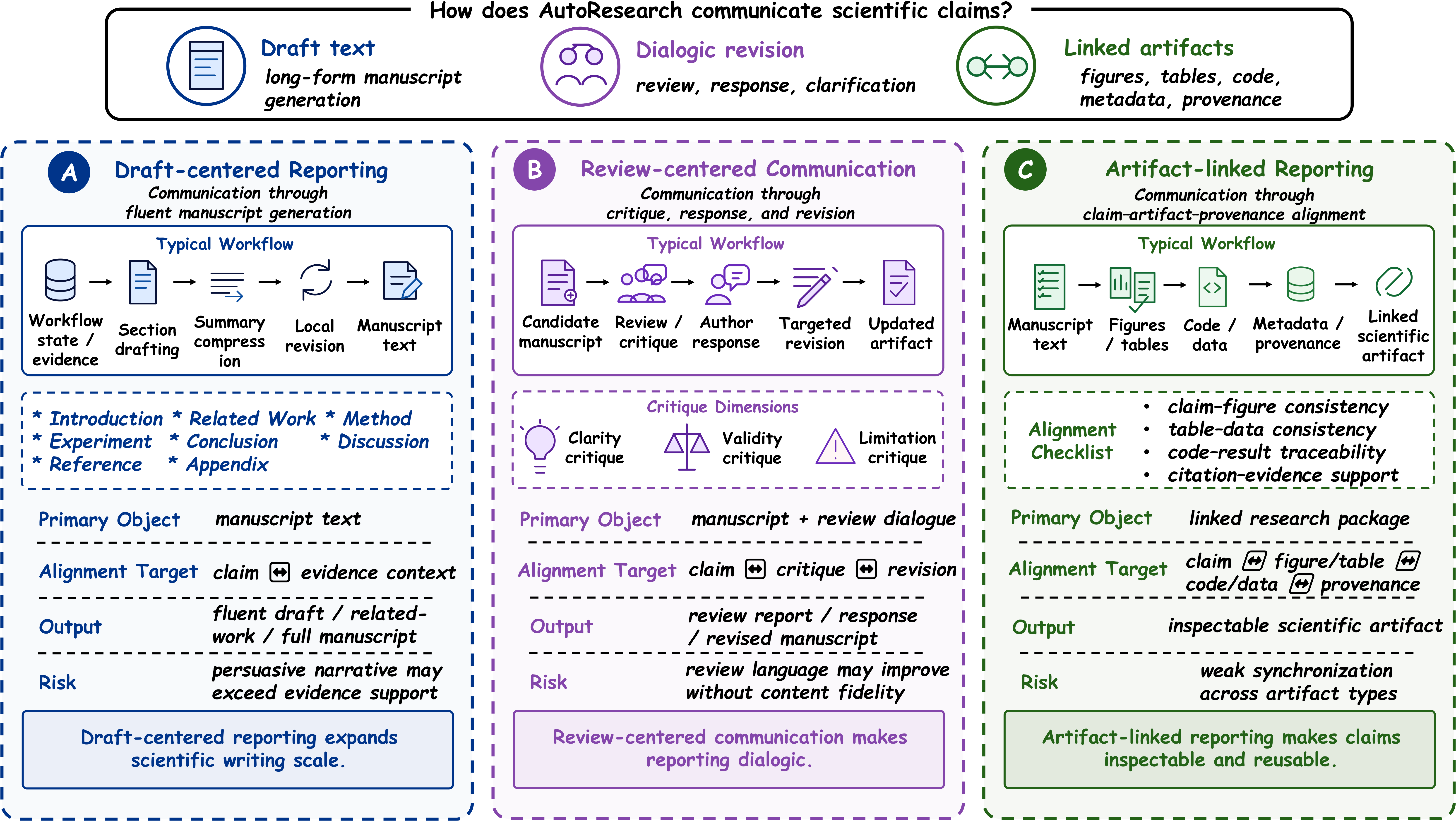
Preserves provenance and claim-evidence alignment in final outputs.
The survey argues that scientific automation is advancing faster than scientific verifiability. Evaluation therefore has to move beyond task-level correctness and ask whether an entire workflow can sustain scientific quality.
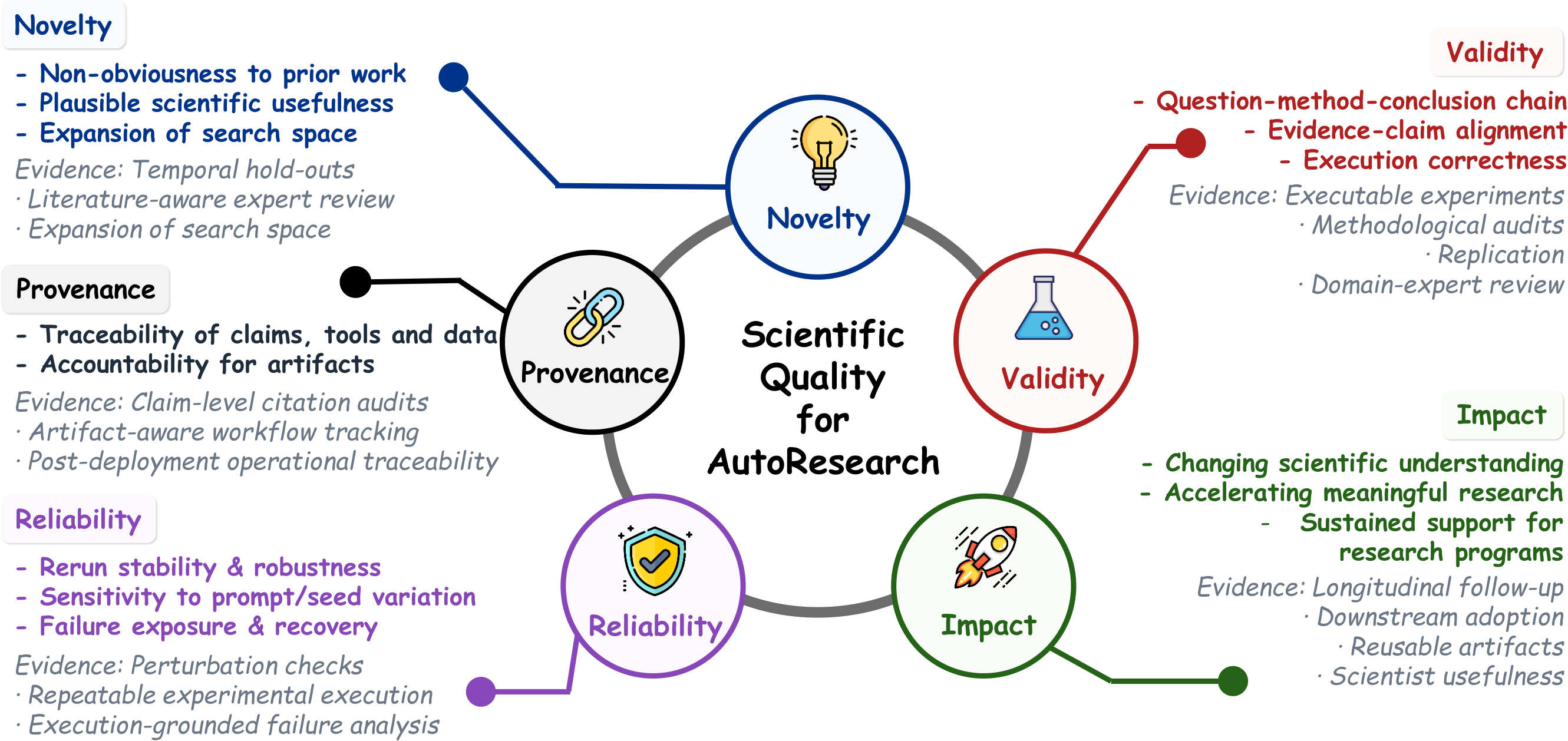
Measures whether a system expands the scientific search space with genuinely new questions, hypotheses, or design choices.
Checks that methods, execution traces, and final claims remain scientifically defensible under scrutiny.
Asks whether outputs matter for downstream scientific progress, not merely whether they are technically correct.
Evaluates stability across reruns, perturbations, tool changes, and long-horizon workflow execution.
Requires that claims can be traced back to sources, tools, data, intermediate steps, and validation outcomes.
Scientific autonomy does not progress uniformly across disciplines. The paper emphasizes that domain structure controls how far workflow closure can realistically go.
These are the most automation-ready settings because workflows are code-native, replayable, and paired with relatively explicit correctness signals.
Autonomy is supported by simulators, optimization pipelines, and instrumented environments, but remains coupled to hardware interfaces and physical experimentation.
These workflows benefit from closed-loop control and automated evaluation, yet are constrained by real-world embodiment, reset cost, and long-horizon deployment friction.
Robotic labs and search-driven experimentation make this a strong candidate for partial workflow autonomy with measurable scientific outputs.
AI can accelerate analysis, protocol design, and multimodal interpretation, but biological systems remain noisy, heterogeneous, and difficult to fully control.
Clinical domains face the tightest accountability, safety, and regulatory constraints, which sharply lowers the ceiling for autonomous scientific closure.
Human behavior, causal ambiguity, and limited manipulability make automated discovery substantially harder than in closed technical environments.
These domains rely on observation, modeling, and slow feedback processes across open systems, creating persistent barriers to end-to-end automation.
The project page is a paper-facing entry point; the repository remains the full survey companion with figures, narrative, and curated references.
@article{tie2026autoresearchai,
title = {AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery},
author = {Guiyao Tie and Jiawen Shi and Dingjie Song and Yixiao Huang and Ziji Sheng and Xueyang Zhou and Daizong Liu and Pan Zhou and Yongchao Chen and Ran Xu and Lifang He and Qingsong Wen and Manling Li and Cong Lu and Shuai Li and Pengtao Xie and Yixuan Yuan and Rui Meng and Lei Xing and Lichao Sun and Caiming Xiong and Philip S. Yu and Jianfeng Gao},
journal = {arXiv preprint arXiv:2605.23204},
year = {2026},
url = {https://arxiv.org/abs/2605.23204}
}